


Deception And Truth Analysis (D.A.T.A.), Inc. has had pre-public access to OpenAI and ChatGPT for over a year and has conducted numerous tests of it and experiments with it. Furthermore, we continue to monitor it, along with other Large Language Models (LLMs) such as Alphabet’s Bard, Meta’s LLaMA AI, Chinchilla, and so on. We monitor LLMs closely to see if people or organizations can rely upon LLMs to replicate or replace our own deception and truth detection capabilities. In other words, is ChatGPT a threat to D.A.T.A.? We do not think so, and here are our Top 10 Reasons…
Top 10 Reasons ChatGPT is Not a Threat to D.A.T.A.
10. D.A.T.A. is more than just its IP.
We believe that D.A.T.A.’s Intellectual Property is innovative and that it has overcome technical challenges faced by others who have attempted to develop similar technologies. That said, D.A.T.A. is much more than just its IP. It is also about a leadership team that has over one hundred years of experience in the investment business. It is about its culture of centering on Client needs and striving to provide white-glove service, and the deep relationships our approach has fostered. Additionally, we believe we have the globe’s only dataset and commensurate set of insights into the norms of deception and truth in finance and investing. That dataset grows every single day and would be difficult to replicate.
9. People Cannot Detect ChatGPT or Deception. Sounds good to D.A.T.A.
It has been demonstrated by researchers that ChatGPT can generate texts that are difficult for people to discern are generated by a computer. Specifically, people can detect AI generated text with only about 50-52% accuracy. Incidentally, this accuracy range is remarkably similar to the accuracy of people attempting to detect deception of any kind; whether that is by audio, visual, or written means. For audiovisual cues people’s detection accuracy is just 54% and people can detect deception in written texts just 50% of the time. So, if anything ChatGPT’s ability to generate bogus text, and people’s inability to detect it, is not a threat to D.A.T.A., but an opportunity.
8. ChatGPT Does Not Use Its Users’ Input to Improve Itself
OpenAI’s Terms of Use §3(c) states that its users’ input is not used “to develop or improve our Services.” In other words, there is not a way for ChatGPT to utilize user input to create a deception detection algorithm. That is, unless one of their users inputs a deception detection algorithm themselves. In this instance, D.A.T.A. would be competing, not with ChatGPT, but with another company’s deception detection algorithm. This is no different to the competition we face every single day.
7. ChatGPT’s Own Terms of Service Seeks to Fight Its Use to Deceive People
OpenAI’s own Terms of Use §2(c)(v) forbids using ChatGPT to “represent that output from the Services was human-generated when it is not or otherwise violate our Usage Policies.” This Term specifically forbids that users use ChatGPT to spoof others. OpenAI and other LLMs also actively monitor improper uses of their technologies.
6. Infinity is an Inappropriate Mental Model for Understanding ChatGPT
Most of us have had the experience of a new technology impressing us at a very deep level, whether that is our first MP3 player, video game console, or smartphone. For many people their interactions with ChatGPT have done exactly this: impressed at a deep level.
Having studied behavioral economics and human psychology for more than two decades D.A.T.A. can attest that a typical response in these moments is for people to try and comprehend new unfamiliar ideas and information by relating them to familiar ideas and information already comprehended via mental models or analogy. But what do people do when their fallback mental models and analogies fail to aid their comprehension?
In these instances, it is tempting to liken things that inspire awe, like ChatGPT, to the Infinite. Evidence of this is that in many of D.A.T.A.’s conversations with investors or Clients where no matter how accurate, thoughtful, or sophisticated our response to their questions about ChatGPT they respond with, “Yeah, that may be true of ChatGPT 3.5, but what about ChatGPT in four additional iterations?” This is evidence of the “Infinite mental model” at work. After all, each of us has had the experience of imagining the largest number we can think of, and we end up with Infinity as the largest number. But then there is the immediate and subsequent thought of “Infinity + 1,” “Infinity + 2,” and of course, “Infinity + Infinity,” and so on.
It is easy to be presented with new evidence and simply say Infinity + 1 and never be satisfied that something can compete with that. But ChatGPT is not infinite, so it is the inappropriate mental model. In fact, as we discuss below, one of the limitations of LLMs like ChatGPT is that they rely on two key things in order to work, both of which are finite.
5. ChatGPT is Ignorant About Deception
D.A.T.A. believes that ChatGPT is highly unlikely to be used to construct a world class deception and truth detection algorithm. Why? Because it is ignorant of deception science and lacks the technical breakthroughs necessary to construct a commercial algorithm. We know this because we asked ChatGPT what it knew about deception detection and it was far off, even reporting something that is a complete fiction, debunked many times by science.
How could ChatGPT be so far off? ChatGPT relies on repackaging information contained on the Internet and the innovative deception and truth technology that is housed within D.A.T.A. is not contained on the Internet.
4. ChatGPT Refuses to Deceive Us
When we ask ChatGPT to deceive us, it refuses to do so. When we try and trick it into deceiving us, it also refuses. Thus, we do not believe ChatGPT can be used to undermine our algorithm. Additionally, when we ask ChatGPT to author a deception and truth algorithm it does not build one. Most importantly, when we ask ChatGPT to “clean” deceptive texts up so that they are less deceptive, while it does alter the scores, it barely does so and thus, it fails to spoof the D.A.T.A. algorithm.
3. LLM Limitations
Large Language Models are similar to lossy compression, such as a Xerox photocopier. In order to be an efficient representation of knowledge, they tend to identify statistical regularities in text and store them in a specialized format. When large computational power is thrown at the task of knowledge retrieval, LLMs can identify extraordinarily nuanced statistical regularities. But, just as a photocopy of a document already photocopied many times is fuzzy, LLMs are quite similar. Their primary shortcomings are that:
a. Garbage In, Garbage Out. LLMs can only answer questions based on the information available to them. In our own tests of ChatGPT in terms of its knowledge of deception detection, the model offered up as a technique something soundly and consistently debunked by science. While this fact was available on the web and has been for over 20 years, ChatGPT seemed to favor popularity of answer over accuracy of answer.
b. Facts Missing, Fabrication Okay. LLMs seem so intent on answering questions that like a Xerox machine asked to copy an image that is already blurry, it answers questions based on inferences that are pure fabrication. That is, LLMs extrapolate information already present even when it results in fabrication. Horrifyingly, it was caught manufacturing a Washington Post article in support of its claim that a professor was guilty of sexual harassment. ChatGPT, similar to the above manufacturing of a Washington Post story to support its conclusions, leaned on a proven false method of detecting deception in ‘avoidance of eye contact.’
2. LLM Text is Easy to Identify
How easy, or how hard is it to detect text generated by ChatGPT? Easy. Multiple researchers have been able to build detectors that have up to a 95% accuracy in classifying texts as authored by LLMs, or other AI. In other words, this is not a difficult problem to solve. Additionally, as we saw above, makers of LLMs want it to be obvious when a document has been authored by AI.
1. Deception Detection is Not an Optimization Problem
LLMs, like all computational models, are optimization problems. Yet, identifying deception is not an optimization problem because there is not just one type of person or even consistent behaviors from individuals. Thus, you need a general solution to account for the variance in people and not a solution whose sole purpose is optimization.
While LLMs are impressive, they rely on directions from their Users. Every single interaction with a LLM, like ChatGPT, a User tells the model what needs to be optimized. Furthermore, many LLM researchers like a recent call for new optimization ideas from MIT believe that better optimization will result in better results.

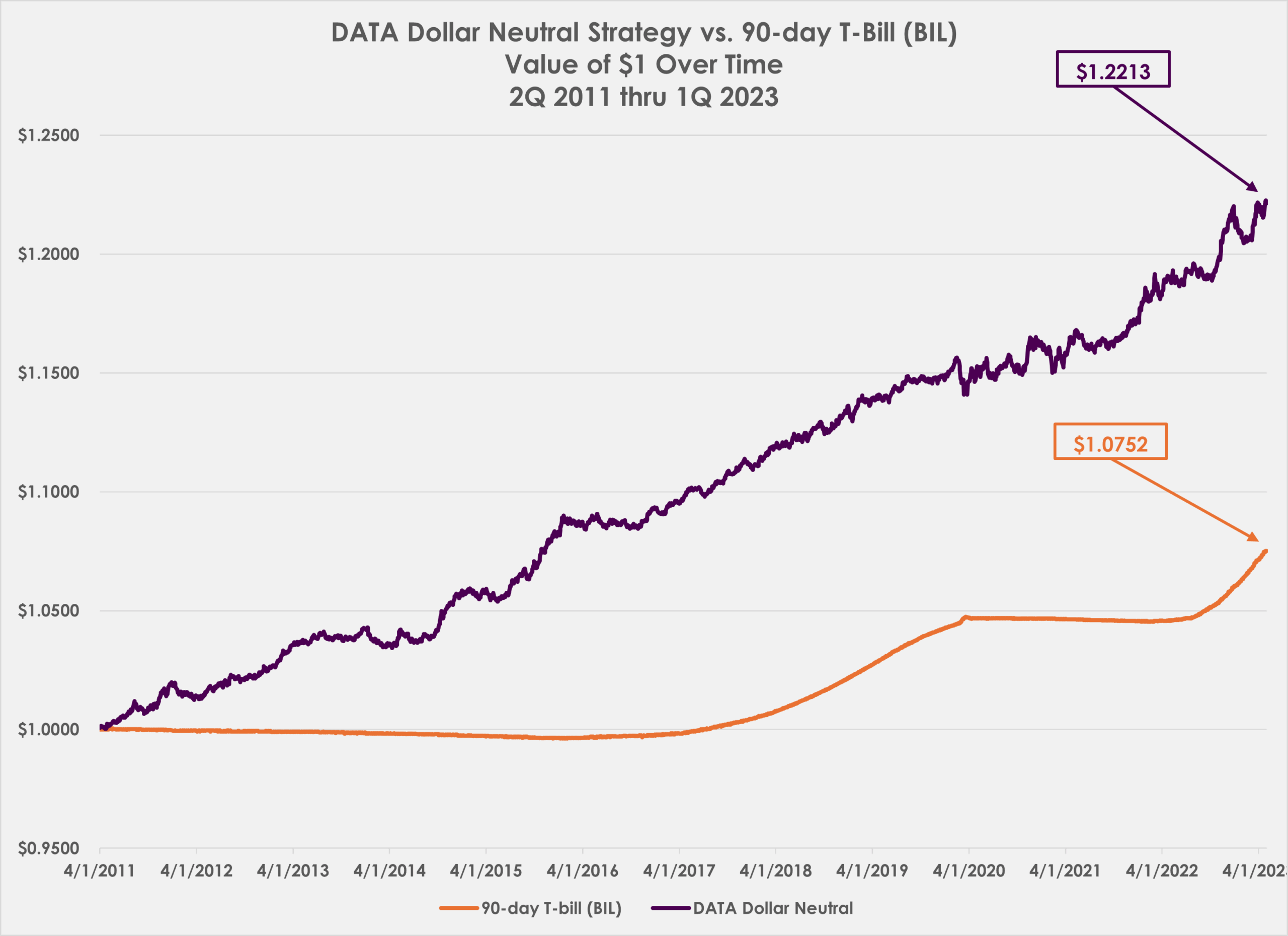
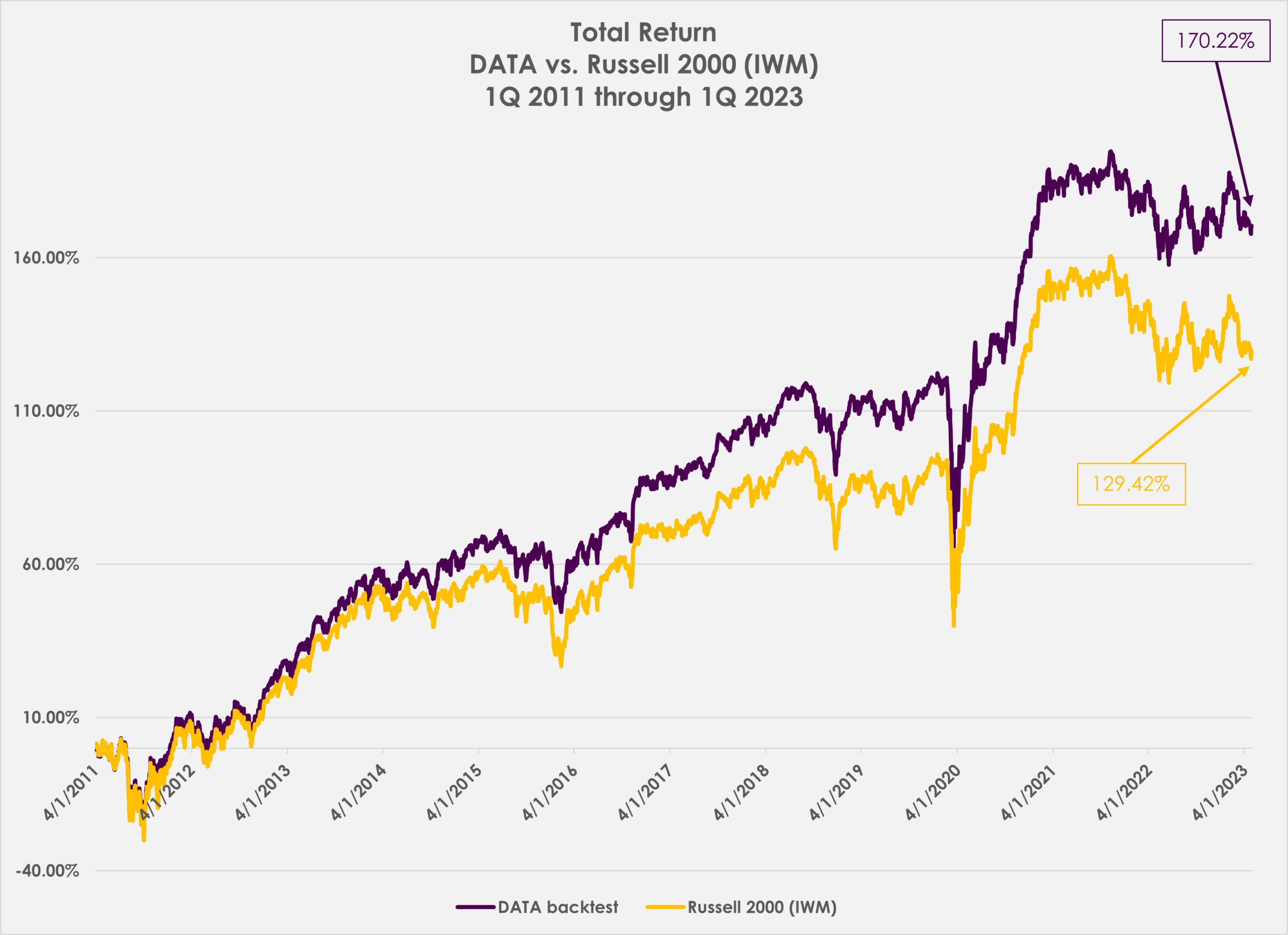
0 Comments